Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation
TL;DR: Teller revolutionizes real-time, audio-driven portrait animation with an innovative autoregressive framework that delivers lifelike, dynamic talking heads. By combining Facial Motion Latent Generation (FMLG) for facial animation and an Efficient Temporal Module (ETM) for refining body movement, it ensures fluid, realistic motion even in small details like neck muscles and accessories. Achieving blazing-fast performance (25 FPS) and outperforming diffusion models by a wide margin, Teller sets a new standard for both animation speed and visual fidelity, offering unmatched realism in audio-driven portrait generation.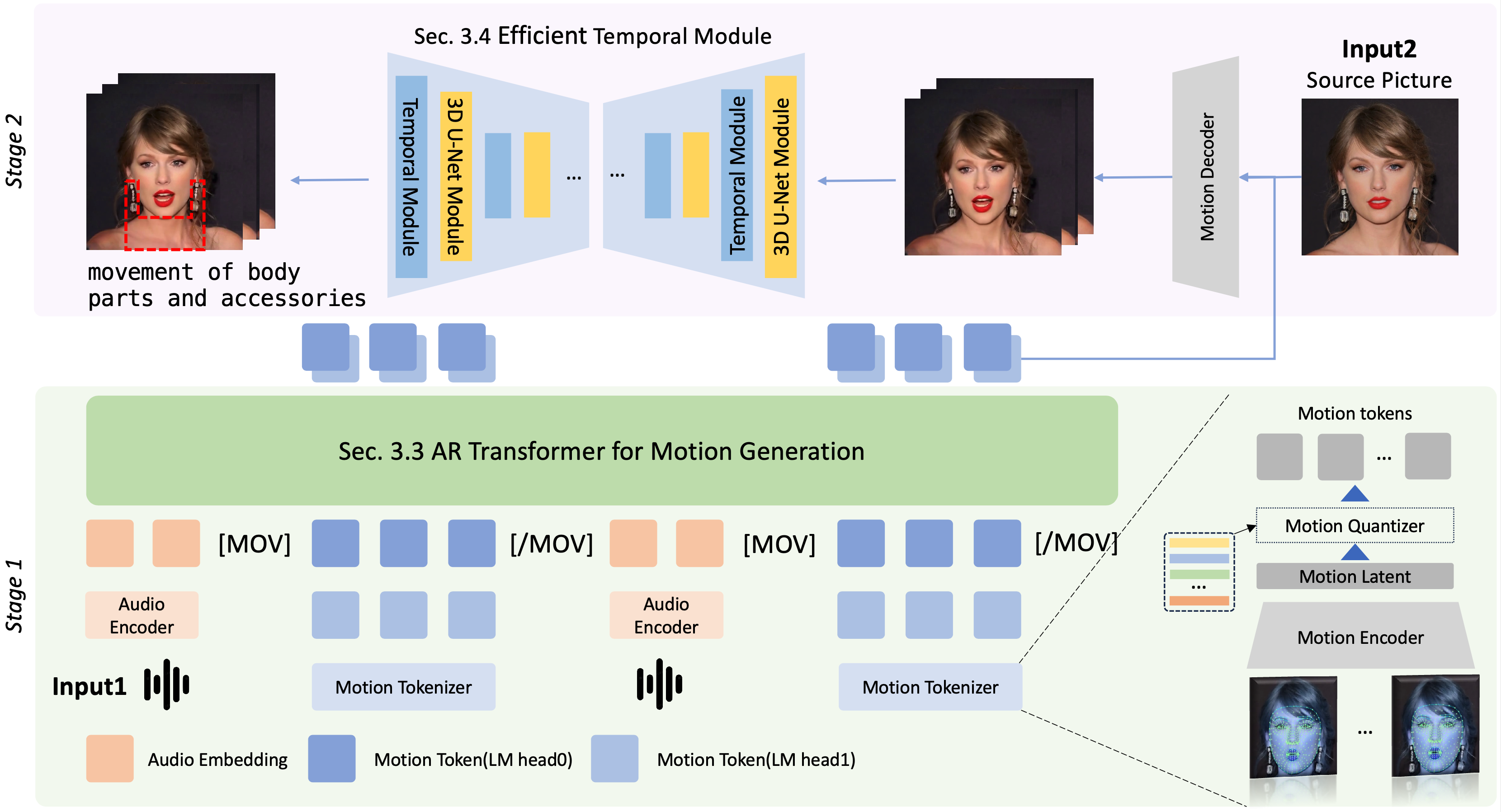
Generated Videos
Teller can generate diverse facial expressions, head movements, realistic body and accessory movements, ensuring physical consistency in animated results.
* Note that all results in this page use the reference image as first frame and conditioned on audio only without need of spatial conditions as templates.
Qualitative comparison with existing approaches on RAVDESS dataset
our model has more accurate emotional expression ability due to the better speech understanding ability of AR transformer.
Angry
Fearful
Disgust
Surprised
Qualitative comparison with existing approaches on HDTF dataset
Teller replicates natural head movements more accurately, closely matching the ground truth (GT) with smooth, realistic turns and subtle expression-based adjustments.